In this project, I dig into the baby name data to produce some interesting findings about baby names over the years to share in the report.
- Track changes in popularity
- Compare popularity across decades
- Compare popularity across regions
- Dig into some unique names
The first objective is to see how the most popular names have changed over time and also to identify the names that have jumped the most in terms of popularity.
- Find the overall most popular girl and boy names and show how they have changed in popularity rankings over the years
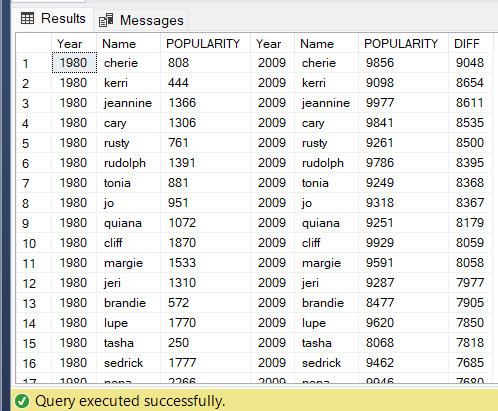
- Find the names with the biggest jumps in popularity from the first year of the data set to the last year
SELECT * FROM names;
SELECT TOP 1 Name, SUM(Births) as Num_Babies
FROM names
WHERE Gender='F'
Group By Name
Order By Num_Babies Desc
; --Jessica
SELECT TOP 1 Name, SUM(Births) as Num_Babies
From names
WHERE Gender='M'
GROUP BY Name
ORDER BY Num_Babies DESC ; -- Michael
-- most populary girl and boy name tracking over the years
WITH Girl_Names AS (SELECT Year,name,SUM(Births) as Num_Babies
FROM names
WHERE Gender = 'F'
GROUP BY Year,Name)
SELECT Year,Name,
ROW_NUMBER() OVER (PARTITION BY Year ORDER BY Num_Babies DESC) AS Popularity
FROM Girl_Names
WHERE Name = 'Jessica';
WITH Boy_Names AS (SELECT Year,name,SUM(Births) AS NUM_Babies
FROM names
WHERE Gender = 'M'
GROUP BY Year,Name)
SELECT YEAR,Name,
ROW_NUMBER() OVER (PARTITION BY Year ORDER BY NUM_Babies DESC ) AS Popularity
From Boy_Names
WHERE Name = 'Michael';
-- The names with biggest jumps in popularity
WITH ALL_NAMES AS( SELECT Year,TRIM(Name) AS Name, COALESCE(SUM(Births),0) AS NUM_BABIES
FROM names
GROUP BY Year,TRIM(Name)
),
NAMES_1980 AS(
SELECT Year,LOWER(Name) AS Name,
ROW_NUMBER() OVER (PARTITION BY Year ORDER BY NUM_BABIES DESC ) AS POPULARITY
FROM ALL_NAMES
WHERE Year = 1980
),
NAMES_2009 AS(
SELECT Year,LOWER(Name) AS Name,
ROW_NUMBER() OVER (PARTITION BY Year ORDER BY NUM_BABIES DESC ) AS POPULARITY
FROM ALL_NAMES
WHERE Year = 2009
)
SELECT T1.Year,T1.Name,T1.POPULARITY,T2.Year,T2.Name,T2.POPULARITY ,
COALESCE(CAST(T2.POPULARITY AS INT),0) - COALESCE(CAST(T1.POPULARITY AS INT),0)AS DIFF
FROM NAMES_1980 T1 INNER JOIN NAMES_2009 T2
ON T1.Name = T2.Name
ORDER BY DIFF DESC;The second objective is to find the top 3 girl names and top 3 boy names for each year, and also for each decade.
- For each year, return the 3 most popular girl names and 3 most popular boy names
- For each decade, return the 3 most popular girl names and 3 most popular boy names
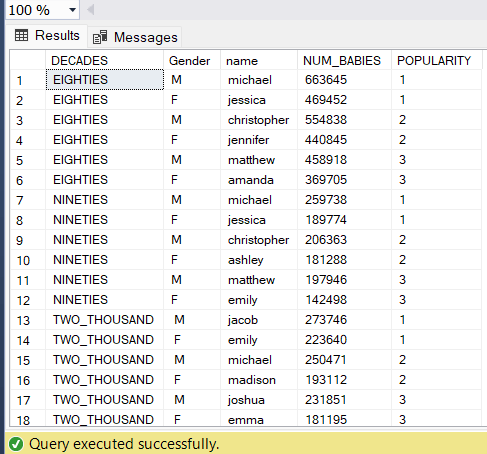
WITH BABIES_BY_DECADES AS (
SELECT
CASE
WHEN Year BETWEEN 1980 AND 1989 THEN 'EIGHTIES'
WHEN Year BETWEEN 1990 AND 1999 THEN 'NINETIES'
WHEN Year BETWEEN 2000 AND 2010 THEN 'TWO_THOUSAND'
ELSE 'NONE'
END AS DECADES,
Gender,
TRIM(name) AS name,
COALESCE(SUM(Births), 0) AS NUM_BABIES
FROM names
GROUP BY
CASE
WHEN Year BETWEEN 1980 AND 1989 THEN 'EIGHTIES'
WHEN Year BETWEEN 1990 AND 1999 THEN 'NINETIES'
WHEN Year BETWEEN 2000 AND 2010 THEN 'TWO_THOUSAND'
ELSE 'NONE'
END,
Gender,
Name
),
TOP_THREE AS (
SELECT
DECADES,
Gender,
LOWER(name) AS name,
NUM_BABIES,
ROW_NUMBER() OVER (PARTITION BY DECADES, Gender ORDER BY NUM_BABIES DESC) AS POPULARITY
FROM BABIES_BY_DECADES
)
SELECT *
FROM TOP_THREE
WHERE POPULARITY < 4
ORDER BY DECADES, POPULARITY;The third objective is to find the number of babies born in each region, and also return the top 3 girl names and top 3 boy names within each region.
- Return the number of babies born in each of the six regions (NOTE: The state of MI should be in the Midwest region)
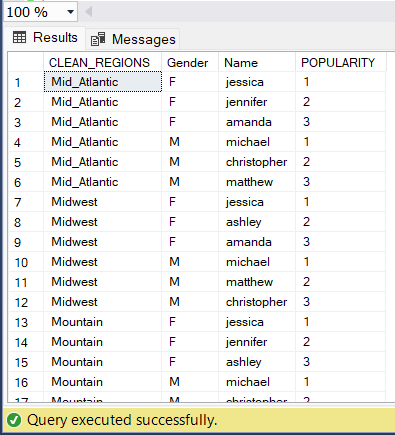
- Return the 3 most popular girl names and 3 most popular boy names within each region
WITH CLEAN_REGIONS AS ( SELECT State,
CASE WHEN Region = 'New England' THEN 'New_England' ELSE Region END AS CLEAN_REGIONS
FROM regions
UNION
SELECT 'MI' AS State , 'Midwest' AS Region)
SELECT CLEAN_REGIONS, SUM(Births) AS NUM_BABIES
FROM names N LEFT JOIN CLEAN_REGIONS CR
ON N.State = CR.State
GROUP BY CLEAN_REGIONS
;
WITH CLEAN_REGIONS AS ( SELECT State,
CASE WHEN Region = 'New England' THEN 'New_England' ELSE Region END AS CLEAN_REGIONS
FROM regions
UNION
SELECT 'MI' AS State , 'Midwest' AS Region),
BABIES_BY_REGION AS (
SELECT CR.CLEAN_REGIONS , TRIM(N.Gender) AS Gender ,LOWER(N.Name) AS Name , SUM(N.Births) AS NUM_BABIES
FROM names N LEFT JOIN CLEAN_REGIONS CR
ON N.State = CR.State
GROUP BY CR.CLEAN_REGIONS , N.Gender , N.Name),
POPULARITY_BY_REGION AS (
SELECT CLEAN_REGIONS,Gender,Name,
ROW_NUMBER () OVER (PARTITION BY CLEAN_REGIONS, Gender ORDER BY NUM_BABIES DESC ) AS POPULARITY
FROM BABIES_BY_REGION)
SELECT * FROM POPULARITY_BY_REGION
WHERE POPULARITY < 4
ORDER BY CLEAN_REGIONS , Gender ;And the final objective is to find the most popular androgynous names, the shortest and longest names, and the state with the highest percentage of babies named “Chris”.
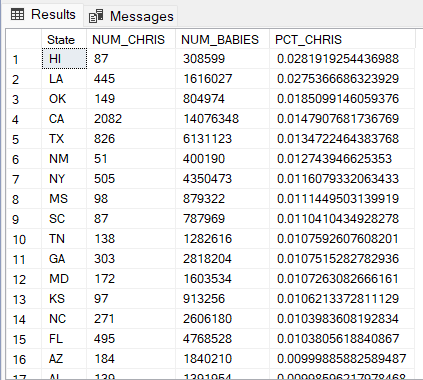
- Find the 10 most popular androgynous names (names given to both females and males)
- Find the length of the shortest and longest names, and identify the most popular short names (those with the fewest characters) and long names (those with the most characters)
SELECT TOP 10 Name,COUNT(DISTINCT TRIM(UPPER(Gender))) AS NUM_GENDERS , SUM(Births) AS NUM_BABIES
FROM names
GROUP BY Name
HAVING COUNT(DISTINCT TRIM(UPPER(Gender))) = 2
ORDER BY NUM_BABIES DESC;
SELECT Name , LEN(Name) as NAME_LENGHT
FROM names
ORDER BY NAME_LENGHT --2 CHARACTERS
;
SELECT Name , LEN(Name) as NAME_LENGHT
FROM names
ORDER BY NAME_LENGHT DESC --16 CHARACTERES
;
WITH SHOR_LONG_NAMES AS ( SELECT *
FROM Names
WHERE LEN(Name) IN (2,16))
SELECT Name,SUM(Births) AS NUM_BABIES
FROM SHOR_LONG_NAMES
GROUP BY Name
ORDER BY NUM_BABIES DESC ;
WITH CHRIS_NUMS AS (SELECT State , SUM(Births) AS NUM_CHRIS
FROM names
WHERE Name = 'Chris'
GROUP BY State) ,
COUNT_ALL_BABIES AS ( SELECT State , SUM(Births) AS NUM_BABIES
FROM names
GROUP BY State)
SELECT CC.State , CC.NUM_CHRIS , CA.NUM_BABIES ,
CAST(NUM_CHRIS AS FLOAT) / CAST(NUM_BABIES AS FLOAT ) * 100 AS PCT_CHRIS
FROM CHRIS_NUMS CC INNER JOIN COUNT_ALL_BABIES CA
ON CC.State = CA.State
ORDER BY PCT_CHRIS DESC;